



Metrics - Learning Data-driven System Design
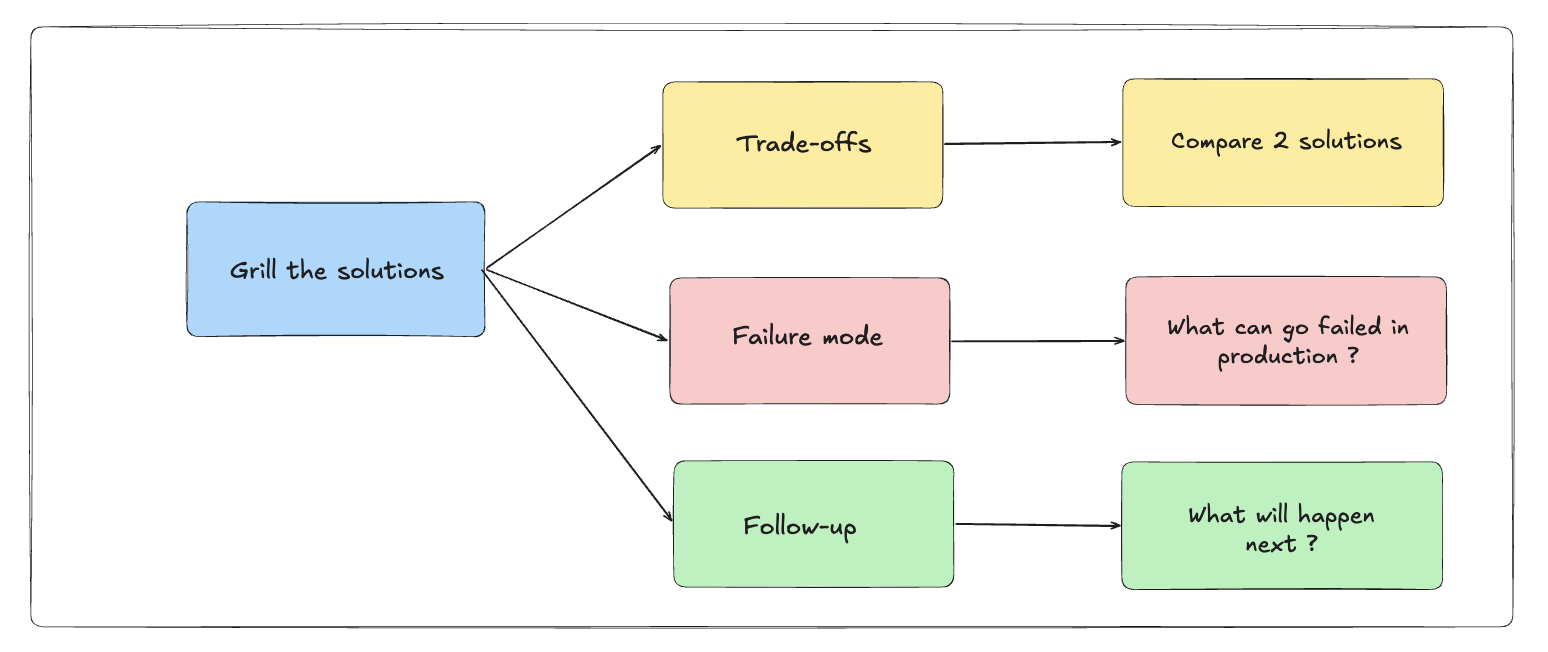
There’s a secret: when you want to persuade a business, nothing is more compelling than solid metrics—they’re hard to dispute and form the strongest basis for meaningful debate.
An experienced software engineer understands the best skill is knowing how to read dashboards and metrics in infrastructures, and using that data to make the right improvements in a system.
1. Temporal Dashboard Metrics
Workflow Metrics
- Workflow execution count — total started, completed, failed, timed out, canceled
- Workflow execution latency — end-to-end duration of workflows
- Workflow task queue backlog — pending workflow tasks waiting to be picked up
- Open workflow count — currently running workflows (watch for unbounded growth)
Activity Metrics
- Activity execution count — started, completed, failed, timed out
- Activity execution latency — time to complete activities
- Activity task queue backlog — pending activity tasks
- Activity retry count — frequent retries signal downstream issues
- Schedule-to-start latency — time between scheduling and worker pickup (high = not enough workers)
Worker Metrics
- Worker poll success rate — are workers successfully polling for tasks?
- Worker task slots available — capacity remaining on workers
- Sticky cache hit rate — workflow cache efficiency
- Worker count per task queue — ensure adequate workers per queue
System / Server Metrics
- Persistence latency — database read/write latency (Cassandra, MySQL, Postgres)
- History service latency — time to load workflow history
- Matching service latency — task dispatch performance
- Frontend service latency — API response times
- gRPC error rate — server-side errors
Critical Alerts to Set Up
| Metric | Condition | Severity |
|---|---|---|
| Schedule-to-start latency | > 5s sustained | High |
| Workflow failure rate | > 5% | High |
| Task queue backlog | growing unbounded | Critical |
| Worker count | drops to 0 for a queue | Critical |
| Persistence latency | p99 > 1s | Medium |
| Activity retry rate | spike above baseline | Medium |
Where to Get These
- Temporal Web UI — workflow status, search, history
- Prometheus + Grafana — Temporal emits metrics via
temporal_*prefix (e.g.,temporal_workflow_completed,temporal_activity_execution_latency) tctlCLI — ad-hoc checks on task queues and namespaces
Tip: Early Warning Signals The most important early warning signals are schedule-to-start latency (worker capacity) and task queue backlog growth (throughput bottleneck).
2. Elasticsearch Dashboard Metrics
Cluster Health
- Cluster status — green (all shards assigned), yellow (replicas unassigned), red (primary shards missing)
- Number of nodes — total data, master, and coordinating nodes in the cluster
- Active shards / Unassigned shards — unassigned shards indicate capacity or config issues
- Relocating / Initializing shards — ongoing shard movements (spikes during rebalancing)
Indexing Performance
- Indexing rate — documents indexed per second (
index_total,index_time_in_millis) - Indexing latency — average time to index a document
- Bulk rejection count — bulk thread pool rejections (sign of write overload)
- Refresh interval / Refresh latency — how often segments are refreshed and how long it takes
- Merge rate / Merge latency — segment merge activity (impacts I/O)
Search Performance
- Search rate — queries per second (
query_total,fetch_total) - Search latency — query + fetch time (
query_time_in_millis,fetch_time_in_millis) - Search rejection count — search thread pool rejections (sign of read overload)
- Scroll open contexts — long-lived scroll contexts consuming memory
- Slow query log count — queries exceeding configured thresholds
Resource Utilization
- JVM heap usage (%) — keep below 75%; GC pressure starts above this
- JVM GC duration & frequency — old-gen GC pauses cause latency spikes
- CPU usage per node — sustained high CPU indicates undersized cluster
- Disk usage per node — ES recommends keeping below 85% (watermark triggers shard relocation)
- File descriptors in use — exhaustion causes indexing/search failures
Thread Pool Metrics
- Active / Queue / Rejected per pool — key pools to watch:
write— indexing operationssearch— query operationsbulk— bulk indexingget— get-by-ID operationsmanagement— cluster management tasks
Circuit Breakers
- Tripped count — parent, fielddata, request, in-flight breakers
- Estimated memory vs limit — how close each breaker is to tripping
Critical Alerts to Set Up
| Metric | Condition | Severity |
|---|---|---|
| Cluster status | yellow > 5min or red | Critical |
| Unassigned shards | > 0 sustained | High |
| JVM heap usage | > 85% | High |
| Disk usage per node | > 85% (high watermark) | Critical |
| Bulk/Search rejections | > 0 sustained | High |
| GC old-gen pause | > 1s | Medium |
| Search latency p99 | > configured SLA | Medium |
| Circuit breaker tripped | any breaker | High |
Where to Get These
- Kibana Stack Monitoring — built-in cluster, node, and index dashboards
_cluster/health— quick cluster status check_nodes/stats— per-node JVM, thread pool, and OS metrics_cat/shards,_cat/indices— shard allocation and index-level stats- Prometheus + elasticsearch_exporter — for Grafana dashboards
- Elastic APM — application-level search/index tracing
Tip: Early Warning Signals The most important early warning signals are JVM heap usage (memory pressure / GC storms), thread pool rejections (cluster overload), and cluster status going yellow/red (data availability risk).
3. MySQL Dashboard Metrics
Connection Metrics
- Threads_connected — current open connections
- Threads_running — actively executing queries (high = contention)
- Max_used_connections — peak connections since last restart
- Connection errors —
Connection_errors_max_connections,Aborted_connects— clients failing to connect - Connection utilization % —
Threads_connected / max_connections(keep below 80%)
Query Performance
- Questions / Queries per second (QPS) — total query throughput
- Slow queries —
Slow_queriescounter; queries exceedinglong_query_time - Query latency (p50, p95, p99) — via Performance Schema or application-side instrumentation
- Select full join / Select full range join — queries doing full table scans in joins (missing indexes)
- Sort merge passes — high values indicate
sort_buffer_sizetoo small - Created_tmp_disk_tables — temp tables spilling to disk (query optimization needed)
InnoDB Metrics
- Buffer pool hit rate —
Innodb_buffer_pool_read_requests / (read_requests + reads)— target > 99% - Buffer pool usage — pages used vs total pages
- Row lock waits / Row lock time —
Innodb_row_lock_waits,Innodb_row_lock_time_avg - Deadlocks —
Innodb_deadlockscounter - InnoDB I/O —
Innodb_data_reads,Innodb_data_writes,Innodb_os_log_written - Dirty pages % — pages modified but not yet flushed
- Redo log throughput — log writes per second; bottleneck if disk is slow
Replication Metrics
- Seconds_Behind_Master — replication lag (critical for read replicas)
- Slave_IO_Running / Slave_SQL_Running — replication thread status
- Relay_Log_Space — size of relay logs on replica
- GTID executed gap — gaps in GTID sets indicate missed transactions
- Semi-sync replication ack latency — time for replica to acknowledge writes
Resource Utilization
- CPU usage — per-core utilization; MySQL is often single-thread bound per query
- Disk I/O (IOPS, throughput, latency) — read/write separately; InnoDB is I/O heavy
- Disk space — data dir, binlog, tmp, redo/undo logs
- Memory usage — buffer pool + per-connection buffers (
sort_buffer,join_buffer,tmp_table_size) - Network traffic — bytes sent/received (
Bytes_sent,Bytes_received)
Table & Index Metrics
- Table open cache misses —
Table_open_cache_misses/Table_open_cache_hits - Handler reads —
Handler_read_rnd_next(full scans),Handler_read_key(index lookups) - Index usage ratio — ratio of index reads to full scans
- Table size growth — largest tables and their growth rate
- Fragmentation —
DATA_FREEininformation_schema.TABLES
Critical Alerts to Set Up
| Metric | Condition | Severity |
|---|---|---|
| Replication lag | > 30s sustained | Critical |
| Slave_IO/SQL_Running | not “Yes” | Critical |
| Connection utilization | > 80% of max_connections |
High |
| Threads_running | > 2x CPU cores sustained | High |
| Buffer pool hit rate | < 99% | Medium |
| Deadlocks | > 0 per minute | Medium |
| Slow queries | spike above baseline | Medium |
| Disk usage | > 85% | High |
| Created_tmp_disk_tables | growing trend | Medium |
Where to Get These
SHOW GLOBAL STATUS— counters for connections, queries, InnoDB, replicationSHOW GLOBAL VARIABLES— current server configuration- Performance Schema — query-level latency, lock waits, table I/O
information_schema— table sizes, index stats, processlist- Prometheus + mysqld_exporter — for Grafana dashboards
- PMM (Percona Monitoring and Management) — all-in-one MySQL monitoring
- Slow query log — detailed analysis of problematic queries
Tip: Early Warning Signals The most important early warning signals are replication lag (data consistency risk), Threads_running spikes (query contention / missing indexes), and buffer pool hit rate drop (working set exceeds memory).
4. Redis Dashboard Metrics
Connection Metrics
- connected_clients — current client connections
- blocked_clients — clients waiting on blocking calls (
BLPOP,BRPOP,XREAD) - rejected_connections — connections refused due to
maxclientslimit - connected_slaves — number of replicas connected (replication topology health)
Performance / Throughput
- instantaneous_ops_per_sec — commands processed per second
- hit rate —
keyspace_hits / (keyspace_hits + keyspace_misses)— target > 95% - Latency per command — via
INFO commandstatsorLATENCY LATEST - Slow log entries — commands exceeding
slowlog-log-slower-thanthreshold
Memory Metrics
- used_memory vs maxmemory — current consumption vs configured limit
- used_memory_rss — actual OS memory (includes fragmentation overhead)
- Memory fragmentation ratio —
mem_fragmentation_ratio= RSS / used_memory; healthy ~1.0–1.5, > 1.5 = fragmentation, < 1.0 = swapping - Evicted keys — keys removed due to
maxmemory-policy; non-zero means cache is full - expired_keys — keys removed by TTL expiration (normal, but watch for spikes)
Persistence Metrics
- rdb_last_bgsave_status — success/failure of last RDB snapshot
- rdb_last_bgsave_time_sec — duration of last snapshot
- aof_rewrite_in_progress — AOF rewrite active (I/O intensive)
- aof_last_write_status — last AOF write result
- rdb_changes_since_last_save — unflushed changes (data loss risk if crash)
Replication Metrics
- master_link_status —
upordownon replica - master_last_io_seconds_ago — seconds since last communication with master
- repl_backlog_size — replication buffer size; too small = full resync on reconnect
- slave_repl_offset vs master_repl_offset — replication lag in bytes
CPU & System
- used_cpu_sys / used_cpu_user — Redis CPU consumption
- used_cpu_sys_children — CPU used by background processes (RDB save, AOF rewrite)
- instantaneous_input_kbps / instantaneous_output_kbps — network bandwidth
Key & Keyspace Metrics
- db0:keys — total keys per database
- Key growth rate — are keys accumulating unexpectedly?
- TTL distribution — percentage of keys with/without expiry
- Big keys — keys consuming disproportionate memory (use
redis-cli --bigkeys)
Cluster Metrics (Redis Cluster mode)
- cluster_state —
okorfail - cluster_slots_assigned / cluster_slots_ok — all 16384 slots should be assigned and ok
- cluster_known_nodes — expected node count
- Migrating / Importing slots — resharding activity
Critical Alerts to Set Up
| Metric | Condition | Severity |
|---|---|---|
| used_memory vs maxmemory | > 90% | Critical |
| Evicted keys | > 0 sustained | High |
| Memory fragmentation ratio | > 1.5 or < 1.0 | High |
| master_link_status | down | Critical |
| rejected_connections | > 0 | High |
| Hit rate | < 95% | Medium |
| rdb_last_bgsave_status | not “ok” | High |
| cluster_state | fail | Critical |
| Slow log entries | spike above baseline | Medium |
| blocked_clients | growing trend | Medium |
Where to Get These
INFOcommand — all sections: server, clients, memory, stats, replication, keyspace, clusterLATENCY LATEST/LATENCY HISTORY— command latency trackingSLOWLOG GET— recent slow commandsMEMORY DOCTOR— memory health diagnosticsredis-cli --bigkeys/--memkeys— key size analysis- Prometheus + redis_exporter — for Grafana dashboards
- Redis Insight — official GUI with real-time monitoring
Tip: Early Warning Signals The most important early warning signals are evicted keys (cache capacity exceeded), memory fragmentation ratio (memory inefficiency or swapping), and hit rate drop (working set changed or cache is thrashing).
5. Apache Spark Dashboard Metrics
Job & Stage Metrics
- Active / Completed / Failed jobs — overall job health
- Job duration — end-to-end wall-clock time per job
- Active / Completed / Failed stages — stages are the unit of parallel execution
- Stage duration & task count — identify slow stages and data skew
- Task failure rate per stage — repeated failures signal bad data or resource issues
Task Metrics
- Task duration distribution — look for outliers indicating data skew or straggler nodes
- Scheduler delay — time between task becoming schedulable and actually launching
- Task deserialization time — high values mean large closures or broadcast variables
- Shuffle read/write time — I/O bottleneck during data exchange between stages
- GC time per task — fraction of task time spent in garbage collection
- Speculative tasks launched — tasks re-launched due to slow executors
Shuffle Metrics
- Shuffle bytes read / written — total data shuffled across the cluster
- Shuffle records read / written — record-level shuffle volume
- Shuffle fetch wait time — time executors spend waiting for shuffle data
- Local vs remote shuffle reads — remote reads are slower; high ratio = poor data locality
- Shuffle spill (memory / disk) — data spilled to disk when memory is insufficient
Executor Metrics
- Active executors — current count vs requested (watch for executor loss)
- JVM heap usage per executor — memory pressure per executor
- GC time per executor — sustained high GC = executor memory too small
- Disk bytes spilled — data evicted from memory to disk
- Input / Output bytes — data read from and written to external storage
- Executor failures / Blacklisted nodes — nodes repeatedly failing tasks
Driver Metrics
- Driver JVM heap usage — the driver collects results; large
collect()ortoPandas()can OOM - Driver GC time — long GC pauses block job scheduling
- DAG scheduler queue size — pending jobs waiting to be scheduled
- Active / Pending stages in scheduler — backlog indicates resource starvation
Memory Metrics
- Storage memory used / available — cached RDDs and broadcast variables
- Execution memory used / available — shuffle, join, sort, aggregation buffers
- Unified memory utilization — storage + execution vs total (
spark.executor.memory) - Off-heap memory — if enabled, track Tungsten off-heap allocation
Streaming Metrics (Spark Structured Streaming)
- Input rate — records/sec ingested from source (Kafka, files, etc.)
- Processing rate — records/sec processed per micro-batch
- Batch duration — time to process each micro-batch
- Scheduling delay — time between batch trigger and actual start
- Watermark delay — event-time watermark lag for late data handling
- State store size — memory used by stateful operations (windowing, dedup)
- Input vs processing rate ratio — if input > processing, backlog grows unbounded
Resource Utilization
- CPU utilization per executor — overall cluster compute usage
- Disk I/O (IOPS, throughput) — shuffle and spill depend heavily on disk
- Network I/O — shuffle-heavy jobs are network bound
- YARN / K8s container memory — actual container memory vs configured limits
- Pending resource requests — tasks waiting for containers/pods
Critical Alerts to Set Up
| Metric | Condition | Severity |
|---|---|---|
| Job failure rate | > 0 unexpected failures | High |
| Executor loss | count drops below expected | Critical |
| GC time per task | > 20% of task duration | High |
| Shuffle spill to disk | sustained non-zero | Medium |
| Driver heap usage | > 80% | High |
| Streaming scheduling delay | growing over time | Critical |
| Input rate > processing rate | sustained | Critical |
| Task duration skew | max > 5x median in a stage | Medium |
| Speculative tasks | spike above baseline | Medium |
| Blacklisted executors | > 0 | High |
Where to Get These
- Spark Web UI — jobs, stages, tasks, storage, executors, SQL, streaming tabs
- Spark History Server — post-mortem analysis of completed applications
/metricsREST endpoint — JSON metrics sink for external consumption- Spark event log — detailed event-level data for debugging
- Prometheus + JMX exporter / Spark metrics sink — for Grafana dashboards
- Ganglia / Graphite sink — built-in Spark metrics sink options
- YARN / Kubernetes dashboards — container-level resource monitoring
- Spark Listener API — custom metric collection via
SparkListener
Tip: Early Warning Signals The most important early warning signals are task duration skew (data skew causing stragglers), shuffle spill to disk (executor memory undersized), and streaming scheduling delay growth (processing can’t keep up with input rate).
6. Envoy Proxy Dashboard Metrics
Upstream (Backend) Metrics
- upstream_rq_total — total requests sent to upstream clusters
- upstream_rq_xx (2xx, 4xx, 5xx) — response code breakdown per upstream cluster
- upstream_rq_time — request latency to upstream (p50, p95, p99)
- upstream_rq_pending_active — requests queued waiting for a connection
- upstream_rq_pending_overflow — requests rejected because pending queue is full
- upstream_rq_retry — retry count; high values indicate flaky upstreams
- upstream_rq_timeout — requests that timed out to upstream
- upstream_cx_active — active connections to upstream hosts
- upstream_cx_connect_fail — failed connection attempts
- upstream_cx_connect_timeout — connection timeouts to upstream
Downstream (Client-facing) Metrics
- downstream_rq_total — total requests received from clients
- downstream_rq_xx (2xx, 4xx, 5xx) — response code breakdown served to clients
- downstream_rq_time — total request latency as seen by the client
- downstream_rq_active — in-flight requests
- downstream_cx_active — active client connections
- downstream_cx_total — total connections since start
- downstream_cx_destroy — connections closed (watch for spikes)
- downstream_cx_rx_bytes / tx_bytes — inbound/outbound traffic volume
HTTP Connection Manager (HCM) Metrics
- downstream_rq_total per route/vhost — traffic distribution across routes
- downstream_rq_too_large — requests exceeding body size limits
- downstream_rq_ws_on_non_ws_route — WebSocket misrouting
Health Check & Outlier Detection
- membership_healthy — healthy hosts per upstream cluster
- membership_degraded — degraded hosts (still receiving traffic at reduced rate)
- membership_total — total hosts in the cluster
- ejections_active — hosts currently ejected by outlier detection
- ejections_total — cumulative ejection count
- ejections_enforced_consecutive_5xx — ejections triggered by consecutive 5xx
- ejections_enforced_success_rate — ejections triggered by low success rate
- health_check.attempt / success / failure — active health check results
Load Balancing Metrics
- upstream_rq_per_host — request distribution across upstream hosts (detect imbalance)
- lb_healthy_panic — panic mode activated (too few healthy hosts, traffic sent to all)
- upstream_cx_pool_overflow — connection pool exhausted
Circuit Breaking
- upstream_rq_pending_overflow — requests rejected by pending request circuit breaker
- upstream_cx_pool_overflow — connections rejected by connection pool circuit breaker
- remaining_pending / remaining_cx / remaining_rq — headroom before circuit breaker trips
Rate Limiting
- ratelimit.ok — requests within rate limit
- ratelimit.over_limit — requests rejected by rate limiter
- ratelimit.error — errors communicating with rate limit service
TLS Metrics
- ssl.connection_error — TLS handshake failures
- ssl.handshake — total TLS handshakes
- ssl.no_certificate — connections without client certificate (if mTLS expected)
- ssl.session_reused — TLS session reuse rate (higher = less handshake overhead)
Resource Utilization
- server.live — Envoy process liveness (0 = draining/shutting down)
- server.memory_allocated — current heap memory usage
- server.memory_heap_size — total heap size
- server.parent_connections / server.total_connections — connection counts during hot restart
- server.concurrency — number of worker threads
- server.watchdog_miss / watchdog_mega_miss — worker thread stuck detection
Critical Alerts to Set Up
| Metric | Condition | Severity |
|---|---|---|
| upstream_rq_5xx rate | > 5% of total | High |
| upstream_cx_connect_fail | spike above baseline | High |
| membership_healthy | < expected count | Critical |
| ejections_active | > 0 sustained | High |
| lb_healthy_panic | triggered | Critical |
| upstream_rq_pending_overflow | > 0 | High |
| downstream_rq_time p99 | > SLA threshold | Medium |
| upstream_rq_retry rate | > 10% of requests | Medium |
| server.watchdog_mega_miss | > 0 | Critical |
| ratelimit.over_limit | spike above baseline | Medium |
Where to Get These
/stats— Envoy admin endpoint; all counters, gauges, histograms in text or JSON/stats/prometheus— Prometheus-formatted metrics endpoint/clusters— per-upstream-host health, active connections, request counts/server_info— version, uptime, command line flags/config_dump— current running configuration- Prometheus + Grafana — scrape
/stats/prometheusdirectly - Istio dashboards — if running as Istio sidecar, Kiali/Grafana dashboards include Envoy metrics
- Envoy access logs — per-request detail including response flags (
UH,UF,NR, etc.)
Tip: Early Warning Signals The most important early warning signals are upstream 5xx rate (backend degradation), ejections_active (outlier detection removing hosts), and upstream_rq_pending_overflow (circuit breaker tripping due to upstream overload).
7. Apache Kafka Dashboard Metrics
Broker Metrics
- ActiveControllerCount — exactly 1 broker should be the controller; 0 = no leader election, > 1 = split brain
- UnderReplicatedPartitions — partitions where ISR < configured replicas (data durability risk)
- OfflinePartitionsCount — partitions with no active leader (unavailable for reads/writes)
- IsrShrinksPerSec / IsrExpandsPerSec — ISR membership changes; frequent shrinks = broker instability
- UncleanLeaderElectionsPerSec — leader elected from out-of-sync replica (potential data loss)
- LeaderCount per broker — leader distribution; imbalance = hot brokers
- PartitionCount per broker — partition distribution across the cluster
Producer Metrics
- record-send-rate — records/sec sent by producers
- record-error-rate — failed produce requests
- request-latency-avg / request-latency-max — produce request latency
- batch-size-avg — average batch size; too small = inefficient, too large = latency
- records-per-request-avg — batching efficiency
- buffer-available-bytes — producer buffer memory remaining; 0 = producer is blocked
- waiting-threads — threads blocked waiting for buffer space
Consumer Metrics
- Consumer lag (records) —
log-end-offset - current-offsetper partition per consumer group - Consumer lag (time) — estimated time to catch up based on consumption rate
- records-consumed-rate — records/sec consumed
- fetch-latency-avg — time to fetch a batch from broker
- commit-latency-avg — time to commit offsets
- rebalance-rate-per-hour — consumer group rebalances; frequent = unstable consumers
- assigned-partitions — partitions assigned to each consumer (detect imbalance)
Topic Metrics
- MessagesInPerSec — write throughput per topic
- BytesInPerSec / BytesOutPerSec — byte-level throughput per topic
- FailedFetchRequestsPerSec / FailedProduceRequestsPerSec — request failures per topic
- Log size per partition — disk usage and growth rate
- Log segment count — number of segments per partition
Request / Network Metrics
- RequestsPerSec — by request type (Produce, Fetch, Metadata, etc.)
- TotalTimeMs — total request time = queue + local + remote + response send
- RequestQueueTimeMs — time request waits in broker queue (high = broker overloaded)
- LocalTimeMs — time for leader to process locally
- RemoteTimeMs — time waiting for followers (replication)
- ResponseQueueTimeMs / ResponseSendTimeMs — response pipeline latency
- NetworkProcessorAvgIdlePercent — network thread idle %; < 30% = network bottleneck
- RequestHandlerAvgIdlePercent — request handler idle %; < 30% = CPU bottleneck
ZooKeeper Metrics (if applicable)
- ZooKeeperRequestLatencyMs — broker-to-ZK latency
- ZooKeeperSessionExpirePerSec — session expirations (triggers leader re-election)
- ZooKeeperDisconnectsPerSec — connection drops to ZK ensemble
KRaft Metrics (ZooKeeper-less mode)
- MetadataLogEndOffset — metadata log progress
- LastAppliedRecordOffset — how current the broker’s metadata is
- MetadataLoadRetryCount — metadata load failures on startup
Resource Utilization
- CPU usage per broker — watch for hot brokers due to leader imbalance
- Disk usage per broker / per log dir — Kafka is disk-intensive
- Disk I/O (read/write IOPS, throughput) — fetch and produce are I/O bound
- Network bandwidth per broker — replication + client traffic
- JVM heap usage — broker heap; page cache matters more than heap for Kafka
- OS page cache hit rate — Kafka relies heavily on OS page cache for reads
- File descriptor count — each partition segment + connections use FDs
Critical Alerts to Set Up
| Metric | Condition | Severity |
|---|---|---|
| OfflinePartitionsCount | > 0 | Critical |
| UnderReplicatedPartitions | > 0 sustained | High |
| ActiveControllerCount | != 1 | Critical |
| UncleanLeaderElectionsPerSec | > 0 | Critical |
| Consumer lag | growing over time | High |
| Consumer rebalance rate | > 1/hour | Medium |
| RequestHandlerAvgIdlePercent | < 30% | High |
| NetworkProcessorAvgIdlePercent | < 30% | High |
| Disk usage per broker | > 80% | High |
| Producer record-error-rate | > 0 sustained | Medium |
| ISR shrinks | frequent without corresponding expands | High |
Where to Get These
- JMX MBeans — all Kafka metrics exposed via JMX (
kafka.server:*,kafka.network:*,kafka.log:*) kafka-consumer-groups.sh --describe— consumer group lag per partition- Prometheus + JMX exporter / kafka_exporter — for Grafana dashboards
- Confluent Control Center — commercial all-in-one Kafka monitoring
- Burrow — LinkedIn’s consumer lag monitoring tool
- AKHQ / Kafka UI — open-source web UIs with topic/consumer visibility
- Cruise Control — LinkedIn’s tool for broker load balancing and self-healing
Tip: Early Warning Signals The most important early warning signals are consumer lag growth (consumers falling behind producers), UnderReplicatedPartitions (broker or disk failure risking data loss), and RequestHandlerAvgIdlePercent drop (broker approaching CPU saturation).
8. Kubernetes Dashboard Metrics
Cluster-Level Metrics
- Node count — total, ready, not-ready nodes
- Cluster CPU / Memory allocatable vs requested vs used — capacity planning overview
- Pod count — total, running, pending, failed, evicted across the cluster
- Namespace resource quotas — utilization vs limits per namespace
Node Metrics
- Node condition —
Ready,MemoryPressure,DiskPressure,PIDPressure,NetworkUnavailable - CPU usage vs allocatable — per-node compute saturation
- Memory usage vs allocatable — per-node memory saturation
- Disk usage (rootfs, imagefs) — kubelet garbage collection triggers at thresholds
- Pod density — pods running vs
maxPodslimit per node - Network in/out per node — bandwidth consumption
- Kernel OOM kills — out-of-memory kills at the OS level (not always visible in K8s events)
Pod & Container Metrics
- Pod status — Running, Pending, CrashLoopBackOff, ImagePullBackOff, Evicted, OOMKilled
- Container restarts —
kube_pod_container_status_restarts_total; frequent restarts = crash loop - CPU usage vs requests vs limits — per container; throttled if exceeding limit
- CPU throttling —
container_cpu_cfs_throttled_periods_total / container_cpu_cfs_periods_total; > 25% = limit too low - Memory usage vs requests vs limits — per container; OOMKilled if exceeding limit
- Pod scheduling latency — time from creation to running
- Pod startup duration — init containers + pull + start time
Deployment & Workload Metrics
- Desired vs available vs ready replicas — per Deployment, StatefulSet, DaemonSet
- Rollout progress —
kube_deployment_status_observed_generationvsmetadata.generation - Failed rollouts — deployments stuck in progressing state
- HPA current vs desired replicas — autoscaler behavior
- HPA scaling events — scale-up/down frequency
- Job success / failure count — CronJob and Job completion status
Control Plane Metrics
- API server request rate —
apiserver_request_totalby verb, resource, code - API server request latency —
apiserver_request_duration_seconds(p99) - API server error rate — 5xx responses from kube-apiserver
- etcd request latency —
etcd_request_duration_seconds; > 100ms = etcd bottleneck - etcd db size — growing unbounded = compaction issues
- etcd leader changes — frequent changes = cluster instability
- Scheduler pending pods —
scheduler_pending_pods; pods waiting to be scheduled - Scheduler attempt duration — time to make scheduling decisions
- Controller manager work queue depth — backlog in reconciliation loops
Networking Metrics
- Service endpoint count — endpoints backing each service (0 = no healthy pods)
- CoreDNS query rate / latency / errors — DNS resolution performance
- CoreDNS cache hit rate — low = excessive upstream lookups
- Ingress controller request rate / latency / error rate — per host/path
- Network policy drops — packets dropped by NetworkPolicy rules
- Pod-to-pod latency — cross-node communication performance
Storage Metrics
- PersistentVolume status — Bound, Available, Released, Failed
- PVC usage vs capacity — volume fill percentage
- Volume mount latency — time to attach and mount volumes
- CSI driver errors — storage provisioning or attach failures
Resource Quota & Limits
- ResourceQuota usage vs hard limit — per namespace
- LimitRange violations — pods rejected due to limit range policies
- Pending pods due to insufficient resources —
FailedSchedulingevents
Critical Alerts to Set Up
| Metric | Condition | Severity |
|---|---|---|
| Node NotReady | any node not ready > 5 min | Critical |
| Pod CrashLoopBackOff | any pod in crash loop | High |
| Pod OOMKilled | any occurrence | High |
| CPU throttling | > 25% throttled periods | Medium |
| Pending pods | > 0 sustained > 5 min | High |
| Deployment replicas unavailable | desired != available | High |
| etcd request latency p99 | > 200ms | High |
| API server 5xx rate | > 1% | Critical |
| PVC usage | > 85% capacity | High |
| Node DiskPressure | condition true | Critical |
| HPA at max replicas | sustained at ceiling | Medium |
| CoreDNS error rate | > 1% | High |
Where to Get These
- Kubernetes Dashboard — built-in web UI for cluster overview
kubectl top nodes / pods— real-time resource usage (requires metrics-server)- Metrics Server — lightweight in-cluster resource metrics (CPU/memory)
- Prometheus + kube-state-metrics —
kube_*metrics for object states (pods, deployments, nodes) - Prometheus + cAdvisor —
container_*metrics for container-level resource usage - Prometheus + node_exporter — OS-level node metrics
- Grafana + kubernetes-mixin dashboards — community-maintained K8s dashboard set
kubectl describe node/pod— events, conditions, resource allocationkubectl get events --sort-by=lastTimestamp— cluster event stream- Lens / k9s — developer-friendly K8s monitoring tools
- Datadog / New Relic / Dynatrace — commercial full-stack K8s observability
Tip: Early Warning Signals The most important early warning signals are Pending pods (resource exhaustion or scheduling issues), CPU throttling (limits too tight causing performance degradation), and etcd latency (control plane bottleneck affecting all cluster operations).
9. PostgreSQL Dashboard Metrics (Unique vs MySQL)
Info: Scope This section covers only PostgreSQL-specific metrics that have no MySQL equivalent. For shared concepts (connections, query throughput, replication lag, slow queries, buffer hit rate, disk/CPU), refer to 3. MySQL Dashboard Metrics.
Autovacuum & Dead Tuple Bloat
- Dead tuples per table —
pg_stat_user_tables.n_dead_tup; dead rows from MVCC not yet vacuumed - Live-to-dead tuple ratio — high dead ratio = vacuum falling behind
- Autovacuum runs per table —
autovacuum_count,autoanalyze_count - Last autovacuum / autoanalyze timestamp — tables not vacuumed recently are at risk
- Autovacuum workers active — current vs
autovacuum_max_workers; all busy = tables queued - Table bloat estimate — wasted space from dead tuples and fragmentation (use
pgstattupleorpg_bloat_check) - Index bloat — B-tree indexes accumulate bloat; requires
REINDEXorpg_repack
Transaction ID (XID) Wraparound
- Age of oldest unfrozen XID per database —
age(datfrozenxid)frompg_database - Age of oldest unfrozen XID per table —
age(relfrozenxid)frompg_class - Distance to XID wraparound — 2^31 (~2.1 billion) minus current age; if this reaches 0, Postgres shuts down to prevent corruption
- Autovacuum freeze progress — is aggressive vacuum keeping up with XID consumption rate?
Danger: XID Wraparound This is a Postgres-only catastrophic failure mode. If
age(datfrozenxid)approaches 2 billion, the database will refuse all writes. MySQL has no equivalent risk.
WAL (Write-Ahead Log) Metrics
- WAL generation rate — bytes/sec of WAL produced (
pg_stat_wal.wal_bytesin PG14+) - WAL archival lag — difference between last generated and last archived WAL segment
- WAL archive failures —
failed_countinpg_stat_archiver - Replication slot retained WAL —
pg_replication_slots.restart_lsnvs current LSN; inactive slots hold WAL indefinitely and can fill disk - WAL buffers full writes —
wal_buffers_fullindicates WAL buffer too small
Replication Slot Monitoring
- Active vs inactive slots — inactive slots retain WAL without consuming it
- Slot lag in bytes —
pg_wal_lsn_diff(pg_current_wal_lsn(), restart_lsn)per slot - Slot lag in time — for logical replication subscribers falling behind
- Logical replication worker status — apply workers running per subscription
Checkpointer Metrics
- Checkpoints timed vs requested —
pg_stat_bgwriter; requested (forced) checkpoints indicatecheckpoint_completion_targetormax_wal_sizetuning needed - Checkpoint duration — time to write and sync dirty pages
- Checkpoint write time / sync time — breakdown of checkpoint I/O
- Buffers written by checkpointer vs bgwriter vs backends — backends writing buffers directly = shared_buffers too small or bgwriter too slow
Connection Process Model
- Process count — Postgres forks a process per connection (heavier than MySQL threads)
- PgBouncer pool utilization — active vs waiting clients; essential since Postgres connections are expensive
- PgBouncer wait time — time clients spend waiting for a pooled connection
- Idle-in-transaction connections —
pg_stat_activitywherestate = 'idle in transaction'; hold locks and prevent vacuum
Lock Monitoring
- Lock waits —
pg_lockswheregranted = false; queries waiting for locks - Lock wait duration — time spent waiting (via
pg_stat_activity.wait_event_type = 'Lock') - Advisory locks held — application-level locks unique to Postgres
- Relation-level locks by type — AccessShare, RowExclusive, AccessExclusive, etc.
TOAST Table Metrics
- TOAST table size per relation — large values stored out-of-line; can bloat separately
- TOAST compression ratio — effectiveness of TOAST compression
pg_stat_statements (Query-Level Stats)
- Top queries by total_exec_time — cumulative time consumers
- Top queries by calls — most frequently executed
- Top queries by mean_exec_time — slowest on average
- Top queries by rows — queries scanning/returning the most rows
- Top queries by shared_blks_hit vs shared_blks_read — cache efficiency per query
Critical Alerts to Set Up
| Metric | Condition | Severity |
|---|---|---|
XID age (datfrozenxid) |
> 500 million | Critical |
| Replication slot lag | growing unbounded | Critical |
| Inactive replication slots | inactive > 1 hour | High |
| Dead tuples ratio | > 20% of live tuples | High |
| Autovacuum workers | all workers busy sustained | High |
| Idle-in-transaction connections | > 0 for > 10 min | Medium |
| WAL archival lag | > 1 segment behind | High |
| Forced checkpoints | > 50% of total checkpoints | Medium |
| Backends writing buffers | sustained non-zero | Medium |
| Table/index bloat | > 30% wasted space | Medium |
Where to Get These
pg_stat_user_tables— per-table vacuum, analyze, dead tuple countspg_stat_activity— active sessions, wait events, idle-in-transactionpg_stat_bgwriter— checkpoint and background writer statspg_stat_wal— WAL generation metrics (PG14+)pg_stat_archiver— WAL archiving statuspg_replication_slots— slot lag and activitypg_stat_statements— query-level performance (extension)pg_locks— current lock statepgstattuple— tuple-level bloat analysis (extension)- Prometheus + postgres_exporter — for Grafana dashboards
- pgMonitor / pgWatch2 — Postgres-specific monitoring stacks
- pg_bloat_check / pg_repack — bloat detection and remediation tools
Tip: Early Warning Signals The most important early warning signals are XID age approaching wraparound (database will shut down), inactive replication slots (disk fill from retained WAL), and dead tuple accumulation (vacuum not keeping up, causing bloat and slow scans).
10. Apache Cassandra Dashboard Metrics
Cluster & Node Health
- Node status — UP/DOWN per node;
nodetool statusshows UN (Up Normal), DN (Down Normal), etc. - Gossip heartbeat — inter-node gossip protocol liveness
- Pending tasks per stage — tasks queued in each thread pool stage (read, mutation, gossip, etc.)
- Dropped messages — messages dropped due to timeouts per verb type (MUTATION, READ, etc.); indicates overload
Read Performance
- Read latency (local) —
ReadLatencyp50, p95, p99 per node and per table - Read latency (coordinator) — full round-trip latency including cross-node reads
- Key cache hit rate — partition key cache; high miss rate = more disk seeks
- Row cache hit rate — optional row-level cache; misses fall through to SSTables
- Bloom filter false positive rate — high rate = unnecessary disk reads per query
- SSTable reads per query —
SSTablesPerReadHistogram; lower = better (indicates compaction effectiveness) - Speculative retries — reads retried on another replica due to slow response
- Tombstone scanned per read — excessive tombstones slow reads and can cause query timeouts
Write Performance
- Write latency (local / coordinator) —
WriteLatencyp50, p95, p99 - Memtable size — in-memory write buffer per table; flushed to SSTable when full
- Memtable flush duration — time to flush memtable to disk
- Pending memtable flushes — queued flushes waiting for I/O
- Commit log size / sync duration — WAL equivalent; sync latency affects write throughput
- Hints stored / Hints in progress — hints queued for downed nodes; large hint backlog = prolonged outage
Compaction Metrics
- Pending compaction tasks — SSTables waiting to be compacted; growing = can’t keep up
- Compaction bytes compacted — throughput of compaction I/O
- SSTable count per table — too many SSTables = slow reads; compaction should reduce this
- Compaction strategy effectiveness — varies by strategy (STCS, LCS, TWCS)
- Partition size distribution — large partitions (“wide rows”) cause compaction and read problems
- Tombstone ratio — high tombstone-to-live ratio indicates deletion-heavy workloads needing TWCS or TTL tuning
Repair Metrics
- Last repair timestamp per table — repairs must run within
gc_grace_secondsto prevent zombie data - Repair duration — time to complete anti-entropy repair
- Pending repair sessions — incremental repair backlog
- Validation compaction time — Merkle tree build time during repair
Thread Pool Stages
- Active / Pending / Blocked per stage — key stages:
MutationStage— write operationsReadStage— read operationsReadRepairStage— read repair background fixesCompactionExecutor— compaction tasksMemtableFlushWriter— memtable flush tasksGossipStage— cluster membership gossipNative-Transport-Requests— client request handling
Consistency & Availability
- Unavailable exceptions — requests that couldn’t meet the requested consistency level
- Read/Write timeouts — requests that timed out waiting for replicas
- CAS contention — lightweight transaction contention (Paxos round failures)
- Read repair count — background consistency fixes triggered by reads
- Hinted handoff success / failure — hint delivery to recovered nodes
Resource Utilization
- JVM heap usage — per-node; Cassandra is sensitive to GC pressure
- GC pause duration & frequency — long GC pauses cause node to appear dead to gossip
- Off-heap memory — bloom filters, compression metadata, partition index stored off-heap
- Disk usage per node — data + commit log + compaction temporary space (compaction needs ~50% free)
- Disk I/O (IOPS, throughput, latency) — compaction and reads are I/O heavy
- CPU usage — compaction and serialization are CPU intensive
- Network I/O — inter-node replication and repair traffic
Critical Alerts to Set Up
| Metric | Condition | Severity |
|---|---|---|
| Dropped messages | > 0 sustained | Critical |
| Pending compaction tasks | growing unbounded | High |
| Node DOWN | any node DN | Critical |
| Read/Write latency p99 | > SLA threshold | High |
| Tombstones scanned per read | > 1000 | High |
| GC pause | > 500ms | High |
| Disk usage | > 50% (compaction headroom) | High |
| Unavailable exceptions | > 0 | Critical |
| Hints stored | growing over time | High |
| SSTable count per table | growing unbounded | Medium |
| Bloom filter false positive % | > 1% | Medium |
| Repair not run | > gc_grace_seconds since last |
Critical |
Where to Get These
nodetool status— node UP/DOWN state and ownershipnodetool tpstats— thread pool stage stats (active, pending, blocked, dropped)nodetool tablestats— per-table read/write latency, SSTable count, bloom filter statsnodetool compactionstats— pending and active compactionsnodetool info— heap, uptime, gossip, data load per node- JMX MBeans — all Cassandra metrics exposed via
org.apache.cassandra.metrics - Prometheus + JMX exporter / cassandra_exporter — for Grafana dashboards
- DataStax MCAC (Metrics Collector) — lightweight metrics agent for Cassandra
- Reaper — automated repair scheduling and monitoring
- Medusa — backup monitoring
Tip: Early Warning Signals The most important early warning signals are dropped messages (node overwhelmed and silently losing requests), pending compaction growth (read performance will degrade as SSTables pile up), and tombstone accumulation (queries scanning tombstones will eventually time out).
11. MongoDB Dashboard Metrics
Replica Set Health
- Replica set status —
rs.status(); each member should be PRIMARY, SECONDARY, or ARBITER - Replication lag —
optimeDatedifference between primary and each secondary - Replication oplog window — hours of operations retained in the oplog; if lag exceeds window, full resync required
- Oplog size & growth rate — oplog consumption rate vs configured size
- Election count — primary elections; frequent = network or node instability
- Heartbeat latency — member-to-member heartbeat round-trip time
Sharding Metrics (Sharded Clusters)
- Chunk count per shard — distribution of chunks across shards (imbalance = hot shard)
- Chunk migrations active — balancer moving chunks between shards
- Jumbo chunks — chunks exceeding max size that can’t be split or migrated
- Balancer state — running/stopped; stopped means no automatic rebalancing
- Config server availability — config servers store shard metadata; outage = no routing changes
- Mongos connection pool — connections from router to each shard
Query Performance
- opcounters —
insert,query,update,delete,getmore,commandper second - Query latency — via
db.serverStatus().opLatencies(reads, writes, commands) - Slow queries — operations exceeding
slowmsthreshold in profiler - Query targeting ratio —
scannedObjects / returned; high ratio = missing or inefficient index - Collection scan count —
COLLSCANin query plans; full scans on large collections - Aggregation pipeline execution time — complex pipelines can be expensive
WiredTiger Storage Engine
- Cache usage —
wiredTiger.cache.bytes currently in the cachevsmaximum bytes configured - Cache dirty bytes — modified pages not yet written to disk; high = write pressure
- Cache eviction — pages evicted from cache; high rate = cache undersized
- Cache read/write pages — I/O activity through the cache
- Checkpoint duration — WiredTiger periodic checkpoint time
- Tickets available (read / write) — WiredTiger concurrency tickets; 0 available = all threads busy, operations queue
Warning: WiredTiger Tickets When read or write tickets hit 0, all new operations of that type queue. This is one of the most common causes of MongoDB “stalls” and is unique to WiredTiger’s concurrency control.
Connection Metrics
- Current connections —
db.serverStatus().connections.current - Available connections — remaining vs
maxIncomingConnections - Connection pool utilization — driver-side pool stats (checked out, wait queue)
- Cursors open —
cursors.totalOpen; unclosed cursors leak resources - Cursors timed out — cursors killed by server after idle timeout
Document & Index Metrics
- Document count & size per collection — growth rate tracking
- Index size per collection — indexes should fit in RAM (WiredTiger cache)
- Index usage stats —
$indexStats; unused indexes waste write performance and memory - TTL deletions per second — TTL index background thread throughput
- Index build progress — foreground/background index builds in progress
Locking Metrics
- Global lock queue — readers/writers waiting for global lock
- Lock % of total time — percentage of time locks are held
- Ticket usage by lock type — intent shared, intent exclusive, shared, exclusive
- CurrentOp long-running operations — operations held open > threshold
Change Streams & Oplog
- Change stream resume token lag — how far behind consumers are
- Oplog first/last entry gap — retention window for oplog-based consumers
- Change stream cursor count — open change streams consuming resources
Resource Utilization
- CPU usage — per mongod/mongos process
- Disk I/O — WiredTiger is I/O bound for eviction and checkpoints
- Disk usage — data files + journal + oplog + index files
- Network I/O — replication + client traffic + shard balancer traffic
- Memory — WiredTiger cache + connection overhead + OS page cache
- File descriptors — each connection + internal files
Critical Alerts to Set Up
| Metric | Condition | Severity |
|---|---|---|
| Replica set member down | any member not PRIMARY/SECONDARY | Critical |
| Replication lag | > 10s sustained | High |
| Oplog window < replication lag | lag exceeds oplog retention | Critical |
| WiredTiger cache usage | > 80% of configured max | High |
| WiredTiger tickets available | read or write = 0 | Critical |
| Query targeting ratio | > 100 (scanned/returned) | Medium |
| COLLSCAN on large collections | any occurrence | Medium |
| Jumbo chunks | > 0 | High |
| Connection utilization | > 80% of max | High |
| Cursors open | growing unbounded | Medium |
| Global lock queue | readers or writers > 0 sustained | High |
| Primary election | unexpected election event | High |
Where to Get These
db.serverStatus()— comprehensive server metrics (connections, opcounters, WiredTiger, locks, replication)db.currentOp()— currently executing operationsrs.status()— replica set member states and replication lagsh.status()— shard distribution, balancer state, chunk countsdb.collection.stats()— per-collection size, index, and storage info$indexStatsaggregation — per-index usage frequency- Database Profiler — slow query capture (
db.setProfilingLevel()) - Prometheus + mongodb_exporter — for Grafana dashboards
- MongoDB Atlas Monitoring — built-in dashboards for Atlas deployments
- Ops Manager / Cloud Manager — on-prem MongoDB monitoring suite
- mongotop / mongostat — CLI real-time monitoring tools
Tip: Early Warning Signals The most important early warning signals are WiredTiger ticket exhaustion (operations stall waiting for concurrency slots), replication lag approaching oplog window (secondaries will need expensive full resync), and query targeting ratio spikes (missing indexes causing full scans).
12. RabbitMQ Dashboard Metrics
Queue Metrics
- Queue depth (messages ready) — messages waiting to be consumed; growing = consumers can’t keep up
- Messages unacknowledged — delivered to consumers but not yet acked; high count = slow consumers or prefetch too high
- Message publish rate — messages/sec entering queues
- Message delivery rate — messages/sec delivered to consumers
- Message acknowledge rate — messages/sec confirmed processed
- Consumer utilization — fraction of time the queue can deliver to consumers (< 100% = consumers idle or prefetch exhausted)
- Queue age (head message age) — age of the oldest message in the queue; growing = processing delay
Exchange Metrics
- Messages published in per exchange — inbound rate per exchange
- Messages routed per exchange — messages that matched a binding
- Messages unroutable — published with
mandatoryflag but no matching queue; returned or dropped - Exchange-to-queue binding count — topology complexity
Connection & Channel Metrics
- Connection count — total client connections; each is a TCP socket + Erlang process
- Channel count — multiplexed channels within connections; each consumes memory
- Connection churn — connections opened/closed per second; high churn = clients not using persistent connections
- Channel churn — same as above for channels
- Blocked connections — connections blocked by flow control (memory or disk alarm triggered)
Consumer Metrics
- Consumer count per queue — 0 consumers = messages accumulating with nobody processing
- Prefetch count — per-consumer prefetch (
basic.qos); too high = unfair distribution, too low = underutilization - Consumer cancel rate — consumers disconnecting unexpectedly
- Redelivery rate — messages delivered more than once (nack + requeue or consumer crash)
Node / Cluster Metrics
- Node status — running/partitioned/down per cluster member
- Network partitions — split-brain events; RabbitMQ may pause or stop minority partition
- Cluster partition handling mode —
pause_minority,autoheal,ignore - Erlang process count — each connection, channel, queue = Erlang process; approaching
+Plimit is dangerous - File descriptors used — each connection + internal sockets; exhaustion blocks new connections
Memory Metrics
- Memory used vs high watermark — when usage exceeds
vm_memory_high_watermark, publishers are blocked - Memory breakdown —
binary(message payloads),connection_readers/writers,queue_procs,msg_index,mnesia - Memory alarm active — true = all publishers are blocked cluster-wide
- Binary references — Erlang binary memory; refc binaries can cause memory spikes between GC cycles
Disk Metrics
- Disk free vs disk limit — when free space drops below
disk_free_limit, publishers are blocked - Disk alarm active — true = all publishers are blocked
- Message store I/O — read/write rates for persistent message storage
- Queue index I/O — index journal reads/writes
Persistence & Paging
- Messages persistent vs transient — persistent messages survive restarts but cost I/O
- Messages paged out — messages evicted from RAM to disk (queue running out of memory)
- Queue RAM vs disk usage — per-queue memory footprint
Mirrored / Quorum Queue Metrics
- Mirror synchronization status — unsynchronized mirrors = data loss risk if primary fails
- Mirror sync rate — how fast mirrors are catching up
- Quorum queue Raft index lag — follower lag behind leader in quorum queues
- Quorum queue leader distribution — leaders should be balanced across nodes
Shovel & Federation (if used)
- Shovel status — running/terminated per shovel link
- Federation link status — running/starting/error per upstream
- Shovel/Federation message rate — cross-cluster transfer throughput
Critical Alerts to Set Up
| Metric | Condition | Severity |
|---|---|---|
| Memory alarm | triggered | Critical |
| Disk alarm | triggered | Critical |
| Network partition | detected | Critical |
| Queue depth | growing unbounded | High |
| Consumer count per queue | drops to 0 | High |
| Messages unacknowledged | growing over time | High |
| Head message age | > SLA threshold | High |
| Erlang process count | > 80% of limit | High |
| File descriptors | > 80% of limit | High |
| Unsynchronized mirrors | > 0 sustained | High |
| Blocked connections | > 0 | High |
| Redelivery rate | spike above baseline | Medium |
Where to Get These
- RabbitMQ Management UI — built-in web dashboard for queues, exchanges, connections, nodes
- Management HTTP API —
/api/overview,/api/queues,/api/nodes,/api/connections rabbitmqctl list_queues— CLI queue inspection (name, messages, consumers)rabbitmqctl status— node-level runtime info (memory, FDs, Erlang processes)rabbitmqctl cluster_status— cluster membership and partition info- Prometheus + rabbitmq_prometheus plugin — built-in Prometheus endpoint (
/metrics) - Prometheus + Grafana — community dashboards for RabbitMQ
rabbitmq-diagnostics— health checks, memory breakdown, runtime info- PerfTest — RabbitMQ benchmarking and load testing tool
Tip: Early Warning Signals The most important early warning signals are memory/disk alarms (all publishers blocked cluster-wide), queue depth growth (consumers not keeping up with producers), and network partitions (split-brain causing data inconsistency or node pause).
13. Nginx Dashboard Metrics
Request Metrics
- Requests per second (RPS) — total request throughput
- HTTP status code distribution — 2xx, 3xx, 4xx, 5xx rates and ratios
- 5xx error rate — server errors; spikes indicate upstream or config issues
- 4xx error rate — client errors; spikes may indicate bad deployments, bot traffic, or missing routes
- Request latency (p50, p95, p99) — time from request received to response sent
- Request size / Response size — average and distribution of payload sizes
- Requests per URI / location — traffic distribution across endpoints
Connection Metrics
- Active connections — currently open connections (from
stub_statusor Plus API) - Accepted connections — total connections accepted since start
- Handled connections — total connections handled;
accepted - handled= dropped connections - Dropped connections —
accepted - handled; non-zero =worker_connectionslimit hit - Reading / Writing / Waiting connections — connection state breakdown:
Reading— reading request headerWriting— sending response to clientWaiting— keep-alive idle connections
Upstream (Reverse Proxy) Metrics
- Upstream response time — time for backend to respond (requires
$upstream_response_timein log) - Upstream connect time — time to establish connection to backend
- Upstream header time — time to receive first byte from backend (TTFB)
- Upstream status codes — per-backend response code distribution
- Upstream server health — active/backup/down per upstream server
- Upstream active connections — connections currently in use per backend
- Upstream failures / fail_timeout — backends marked as failed by health checks
- Upstream keepalive pool — idle keepalive connections to backends
Rate Limiting Metrics
- Requests delayed — requests held by
limit_req(in burst queue) - Requests rejected (503) — requests exceeding burst limit
- Limit zone utilization — shared memory usage for
limit_req_zone/limit_conn_zone
Caching Metrics (if proxy_cache enabled)
- Cache hit / miss / expired / stale / bypass —
$upstream_cache_statusdistribution - Cache hit ratio —
HIT / total— target depends on workload - Cache size on disk — current vs
max_sizeconfigured - Cache loader / manager activity — background cache maintenance
SSL/TLS Metrics
- SSL handshake rate — new TLS connections per second
- SSL handshake time — TLS negotiation latency
- SSL session reuse rate — higher = less handshake overhead
- SSL handshake errors — failed negotiations (cert issues, protocol mismatch)
- Certificate expiry — days until cert expires
Nginx Plus Additional Metrics (commercial)
- Active health check status — per upstream server pass/fail
- DNS resolver metrics — cache hits, misses, timeouts
- Stream (TCP/UDP) metrics — L4 proxy connection and throughput stats
- Zone sync metrics — cluster state sharing across Nginx Plus instances
- Key-value store usage — dynamic configuration store utilization
Worker Process Metrics
- Worker connections used vs
worker_connections— per worker capacity - Worker CPU usage — per worker process
- Worker memory (RSS) — per worker process memory footprint
- Worker count —
worker_processesconfiguration vs running - Accept mutex contention — workers competing for new connections (less relevant with
reuseport)
Resource Utilization
- CPU usage — total Nginx process group
- Memory usage — master + worker processes RSS
- File descriptors — each connection = 1-2 FDs (client + upstream); limit via
worker_rlimit_nofile - Disk I/O — access/error log writes + cache I/O
- Network bandwidth — inbound + outbound traffic
Critical Alerts to Set Up
| Metric | Condition | Severity |
|---|---|---|
| 5xx error rate | > 1% of total requests | High |
| Dropped connections | > 0 sustained | High |
| Upstream response time p99 | > SLA threshold | High |
| Upstream server down | any backend marked failed | Critical |
| Active connections | > 80% of worker_connections |
High |
| Request latency p99 | spike above baseline | Medium |
| Cache hit ratio | drop below baseline | Medium |
| SSL certificate expiry | < 14 days | High |
| Rate limit rejections | spike above baseline | Medium |
| Error log rate | spike in error-level entries | Medium |
Where to Get These
stub_statusmodule — basic metrics: active connections, accepts, handled, requests, reading/writing/waiting (free)- Nginx Plus API —
/api/endpoint with detailed upstream, cache, SSL, stream, zone metrics - Access log parsing —
$status,$request_time,$upstream_response_time,$upstream_cache_status - Error log monitoring — connection errors, upstream failures, SSL errors
- Prometheus + nginx-prometheus-exporter — scrapes
stub_statusfor Grafana - Prometheus + nginx-vts-module — virtual host traffic status (open-source alternative to Plus)
- Amplify — Nginx’s SaaS monitoring agent
- GoAccess / goaccess — real-time access log analyzer
- ELK stack — parse access/error logs via Filebeat + Logstash
Tip: Early Warning Signals The most important early warning signals are dropped connections (
worker_connectionsexhausted), upstream response time spikes (backend degradation visible at the proxy layer), and 5xx error rate increase (backend failures or misconfigurations propagating to clients).
14. gRPC Dashboard Metrics
RPC Metrics (Server-side)
- RPC rate — requests/sec by service, method, and gRPC status code
- RPC latency (p50, p95, p99) — per method; breakdown by unary vs streaming
- gRPC status code distribution —
OK,UNAVAILABLE,DEADLINE_EXCEEDED,RESOURCE_EXHAUSTED,INTERNAL, etc. - Error rate by status code — non-OK responses as percentage of total
- In-flight RPCs — currently active requests (server concurrency)
- RPC message count per call — for streaming RPCs: messages sent/received per stream
Info: gRPC Status Codes vs HTTP gRPC uses its own status codes (not HTTP 4xx/5xx). Key codes to watch:
UNAVAILABLE (14)— server unreachable, connection refused, load balancer issueDEADLINE_EXCEEDED (4)— timeout; client or server too slowRESOURCE_EXHAUSTED (8)— rate limiting, memory, or concurrency limits hitINTERNAL (13)— server bug or unhandled exceptionCANCELLED (1)— client cancelled the requestUNIMPLEMENTED (12)— method not found (deployment/version mismatch)
RPC Metrics (Client-side)
- Client RPC rate — outbound calls per second by target service and method
- Client RPC latency — round-trip time including network + server processing
- Client retry count — retries per method (if retry policy configured)
- Client retry success rate — percentage of retries that succeed
- Hedged request count — hedged RPCs sent (if hedging policy enabled)
HTTP/2 Transport Metrics
- Active HTTP/2 streams per connection — gRPC multiplexes RPCs over HTTP/2 streams; max is
MAX_CONCURRENT_STREAMSsetting - GOAWAY frames received — server requesting client to reconnect (graceful shutdown, load balancer drain)
- RST_STREAM frames — stream-level resets (aborted RPCs)
- PING/PONG latency — HTTP/2 keepalive round-trip (connection health)
- Window update frequency — flow control adjustments; high rate = flow control bottleneck
- Header compression ratio (HPACK) — compression effectiveness for metadata
Connection & Channel Metrics
- Active connections — open HTTP/2 connections
- Connection establishment rate — new connections/sec (high churn = missing keepalive or LB issues)
- Connection failures — TCP connect errors, TLS handshake failures
- Subchannel state — per-backend subchannel:
READY,CONNECTING,TRANSIENT_FAILURE,IDLE,SHUTDOWN - Channel state — overall channel health combining all subchannels
Load Balancing Metrics
- Backend pick distribution — RPCs distributed per backend (detect imbalance)
- Backend health — healthy vs unhealthy backends in the resolver
- Resolver updates — DNS or service discovery changes frequency
- Pick first fallback — fallback to non-preferred backends
Streaming-Specific Metrics
- Stream duration — lifetime of long-lived streams (server-streaming, bidi-streaming)
- Messages per stream — send/receive message count per stream
- Stream message rate — messages/sec for streaming RPCs
- Stream backpressure events — flow control pauses due to slow consumer
- Stream cancellation rate — prematurely terminated streams
Deadline & Timeout Metrics
- Deadline propagation — incoming deadline remaining vs outgoing deadline set
- Deadline exceeded rate per method — which methods are timing out
- Shortest deadline in chain — in service mesh, the tightest deadline in the call chain
- Time remaining at completion — how close successful RPCs are to their deadline (headroom)
Interceptor / Middleware Metrics
- Auth interceptor failures — authentication/authorization rejections
- Rate limiter rejections —
RESOURCE_EXHAUSTEDfrom server-side rate limiting - Payload size (sent / received) — per-RPC message size; watch for unexpectedly large payloads
- Compression ratio — gzip/snappy effectiveness on message payloads
- Metadata size — header/trailer size per RPC
Resource Utilization
- Thread pool active / queued — server executor thread pool (gRPC uses thread pools for request handling)
- Memory usage — per-process; large streaming RPCs can hold buffers
- File descriptors — each HTTP/2 connection = 1 FD
- Network bandwidth — HTTP/2 framing + protobuf payloads + TLS overhead
- CPU usage — protobuf serialization/deserialization + TLS is CPU-bound
Critical Alerts to Set Up
| Metric | Condition | Severity |
|---|---|---|
| UNAVAILABLE rate | > 1% of total RPCs | Critical |
| DEADLINE_EXCEEDED rate | > 5% per method | High |
| INTERNAL error rate | > 0 sustained | High |
| RESOURCE_EXHAUSTED rate | > 0 sustained | High |
| RPC latency p99 | > deadline headroom threshold | High |
| Subchannel TRANSIENT_FAILURE | any backend stuck in failure | High |
| Stream backpressure events | sustained | Medium |
| Connection failure rate | spike above baseline | High |
| GOAWAY rate | spike (indicates rolling restarts or LB drain) | Medium |
| Client retry rate | > 10% of total RPCs | Medium |
Where to Get These
- gRPC built-in stats handlers —
ServerStatsHandler/ClientStatsHandlerfor per-RPC metrics - OpenTelemetry gRPC instrumentation —
otel-grpcinterceptors for traces + metrics - Prometheus + grpc-ecosystem middleware —
go-grpc-prometheus,py-grpc-prometheusinterceptors - Channelz — gRPC’s built-in diagnostic service (
grpc.channelz.v1); exposes channels, subchannels, sockets, servers via gRPC itself - Admin service —
grpc.admin.v1bundles Channelz + CSDS (Client Status Discovery Service) - Envoy / Istio — if gRPC routed through service mesh, sidecar captures all gRPC metrics
- gRPC health checking protocol —
grpc.health.v1.Health/Checkfor service liveness - Jaeger / Zipkin — distributed tracing for cross-service RPC call chains
Tip: Early Warning Signals The most important early warning signals are DEADLINE_EXCEEDED spikes (latency growing beyond client tolerance), UNAVAILABLE errors (backends unreachable indicating infrastructure or load balancer issues), and subchannel TRANSIENT_FAILURE (persistent backend connectivity failure that won’t self-heal).
15. DynamoDB Dashboard Metrics
Capacity & Throughput
- ConsumedReadCapacityUnits / ConsumedWriteCapacityUnits — actual RCU/WCU consumed per table and GSI
- ProvisionedReadCapacityUnits / ProvisionedWriteCapacityUnits — configured capacity (provisioned mode)
- Read/Write capacity utilization % — consumed / provisioned; approaching 100% = throttling imminent
- AccountProvisionedReadCapacityUtilization / Write — account-level capacity usage vs service limits
- ConsumedReadCapacityUnits per partition — uneven consumption = hot partition
Info: On-Demand vs Provisioned In on-demand mode, there are no provisioned capacity units to monitor. Focus on throttling events and per-partition metrics instead. In provisioned mode, track consumed vs provisioned capacity and auto-scaling behavior.
Throttling Metrics
- ReadThrottleEvents / WriteThrottleEvents — requests rejected due to exceeding capacity; this is the most critical DynamoDB metric
- ThrottledRequests — total throttled API calls
- Throttled requests per partition — identifies hot partitions causing throttling even when table-level capacity has headroom
- OnDemandThroughputExceeded — on-demand mode hitting per-partition or table-level throughput limits
Request Latency
- SuccessfulRequestLatency — server-side latency for successful operations (p50, p99)
- Get latency vs Query latency vs Scan latency — breakdown by operation type
- BatchGetItem / BatchWriteItem latency — batch operation performance
- TransactGetItems / TransactWriteItems latency — transaction overhead
Error Metrics
- SystemErrors — DynamoDB internal errors (HTTP 500); rare but indicates service-side issues
- UserErrors — client-side errors (HTTP 400); validation failures, conditional check failures
- ConditionalCheckFailedRequests — failed conditional writes/deletes (expected in optimistic locking patterns, but watch for spikes)
- TransactionConflict — transactions conflicting with each other
Hot Partition Detection
- Partition-level consumed capacity — via CloudWatch Contributor Insights
- Top accessed partition keys — identify keys responsible for most traffic
- Partition split events — DynamoDB splitting partitions due to hot key patterns
- Adaptive capacity activations — DynamoDB borrowing unused capacity from cold partitions to serve hot ones
Global Secondary Index (GSI) Metrics
- GSI ConsumedRead/WriteCapacityUnits — each GSI has its own capacity
- GSI ThrottleEvents — GSI throttling causes the base table write to be throttled too (GSI back-pressure)
- GSI ItemCount / TableSize — GSI size relative to base table
- GSI replication lag — GSI is eventually consistent; lag between base table write and GSI update
Warning: GSI Back-Pressure When a GSI is throttled, it blocks writes to the base table as well. Always provision GSI capacity >= base table write capacity to avoid this.
DynamoDB Streams Metrics
- IteratorAgeMilliseconds — age of the oldest record in the stream not yet read; growing = consumer falling behind
- Stream read throughput — records/sec consumed from the stream
- Shard count — number of stream shards (scales with table partitions)
- GetRecords.Success / Failure — stream read API success rate
DAX (DynamoDB Accelerator) Metrics
- Cache hit rate — item cache + query cache hit ratio
- ItemCacheHits / ItemCacheMisses — individual item lookups
- QueryCacheHits / QueryCacheMisses — query result caching
- Evictions — items evicted from DAX cache (cache full)
- ErrorRequestCount — failed DAX requests
- CPUUtilization / NetworkBytes — DAX cluster node resources
- ConnectionCount — active client connections to DAX
Auto-Scaling Metrics (Provisioned Mode)
- Auto-scaling target utilization — configured target % (typically 70%)
- Scaling actions (up / down) — frequency and timing of capacity adjustments
- Scaling cooldown violations — scaling requests blocked by cooldown period
- Time above target utilization — duration spent above scaling target before adjustment kicks in
Global Tables Metrics
- ReplicationLatency — time to replicate an item to another region
- PendingReplicationCount — items waiting to be replicated
- ReplicationConflicts — concurrent writes to same item in different regions (last-writer-wins)
Backup & Restore
- Point-in-time recovery status — enabled/disabled per table
- Backup size — on-demand backup sizes
- Restore progress — table restore completion status
Critical Alerts to Set Up
| Metric | Condition | Severity |
|---|---|---|
| ReadThrottleEvents | > 0 sustained | High |
| WriteThrottleEvents | > 0 sustained | High |
| SystemErrors | > 0 | Critical |
| Capacity utilization | > 80% of provisioned | High |
| SuccessfulRequestLatency p99 | > 10ms (reads) or > 25ms (writes) | Medium |
| IteratorAgeMilliseconds | growing over time | High |
| GSI throttle events | > 0 (causes base table backpressure) | High |
| ReplicationLatency | > 1s sustained (global tables) | High |
| ConditionalCheckFailedRequests | spike above baseline | Medium |
| TransactionConflict | spike above baseline | Medium |
| DAX cache hit rate | drop below baseline | Medium |
| Hot partition detected | single partition > 3000 RCU or 1000 WCU | High |
Where to Get These
- CloudWatch Metrics — all DynamoDB metrics published to CloudWatch per table, GSI, and account
- CloudWatch Contributor Insights — top partition keys by consumed capacity (hot partition detection)
- AWS X-Ray — distributed tracing for DynamoDB calls from application
- DynamoDB console — capacity, metrics, alarms, and table-level dashboards
- CloudWatch Alarms — set alarms on throttle events, capacity utilization, latency
- AWS CloudTrail — API-level audit logging (control plane operations)
- Service Quotas dashboard — account-level table count, capacity, and API limits
- AWS Trusted Advisor — capacity and cost optimization recommendations
- NoSQL Workbench — data modeling and capacity planning tool
Tip: Early Warning Signals The most important early warning signals are throttle events (capacity exceeded, requests being rejected), hot partition detection (uneven key distribution causing localized throttling despite table-level headroom), and IteratorAgeMilliseconds growth (DynamoDB Streams consumers falling behind, causing stale downstream data).
16. Distributed Tracing (Jaeger / OpenTelemetry)
Core Concepts
- Trace — end-to-end journey of a single request across all services
- Span — a single unit of work within a trace (e.g., one RPC call, one DB query)
- Span context — trace ID + span ID + flags propagated across service boundaries
- Parent-child relationship — spans form a tree/DAG showing the call graph
- Baggage — key-value pairs propagated through the entire trace (cross-cutting context)
Trace-Level Metrics
- Trace duration (end-to-end latency) — total time from root span start to last span end
- Trace depth — number of service hops in the call chain
- Trace span count — total spans per trace; high count = deep call chains or fan-out
- Trace error rate — percentage of traces containing at least one error span
- Trace completeness — percentage of traces with all expected spans (vs incomplete/broken traces)
Span-Level Metrics
- Span duration — time spent in each operation
- Span self-time — span duration minus child span durations (actual work done in this service)
- Span error rate — per service and operation
- Span status codes — OK, ERROR, UNSET per span
- Span events / logs — structured events attached to spans (exceptions, retries, cache misses)
- Span attributes — key-value metadata (HTTP method, DB statement, user ID, etc.)
Service-Level Metrics (RED Method from Traces)
- Rate — requests/sec per service derived from trace data
- Errors — error rate per service and endpoint
- Duration — latency distribution per service and endpoint (p50, p95, p99)
- Service dependencies — auto-discovered service graph from trace data
- Critical path — the longest chain of sequential spans determining end-to-end latency
Latency Breakdown Analysis
- Time spent per service — which service contributes most to total latency
- Network time (gap analysis) — time between parent span end and child span start = network + queuing
- Serialization / deserialization time — if instrumented, time spent marshaling data
- Queue wait time — time a message sits in a queue before processing (async spans)
- Parallel vs sequential execution — identify opportunities for parallelization from span overlap
Sampling Metrics
- Sampling rate — percentage of traces actually captured
- Sampling strategy — probabilistic, rate-limiting, adaptive, or remote-controlled
- Dropped spans — spans lost due to sampling, buffer overflow, or agent capacity
- Sampled vs unsampled trace count — ensure representative sampling across services
- Adaptive sampling decisions — per-service/operation sampling rate adjustments
Info: Sampling Trade-offs Head-based sampling decides at trace start (simple, but may miss rare errors). Tail-based sampling decides after the trace completes (captures all errors/slow traces, but requires buffering all spans temporarily). Jaeger supports both; OpenTelemetry Collector supports tail-based via
tailsamplingprocessor.
Jaeger-Specific Metrics
Jaeger Agent
- jaeger_agent_reporter_batches_submitted — batches sent to collector
- jaeger_agent_reporter_batches_failures — failed batch submissions
- jaeger_agent_reporter_spans_submitted — spans forwarded to collector
- jaeger_agent_thrift_udp_server_packets_processed — UDP packets from instrumented apps
- jaeger_agent_thrift_udp_server_packets_dropped — dropped UDP packets (buffer full)
Jaeger Collector
- jaeger_collector_spans_received — total spans ingested
- jaeger_collector_spans_rejected — spans rejected (validation, queue full)
- jaeger_collector_spans_dropped — spans dropped due to queue overflow
- jaeger_collector_queue_length — internal span processing queue depth
- jaeger_collector_save_latency — time to write spans to storage backend
- jaeger_collector_spans_serviceNames — unique service names seen (cardinality tracking)
Jaeger Query
- jaeger_query_requests_total — UI/API query count
- jaeger_query_latency — query response time
- jaeger_query_errors — failed trace lookups
Storage Backend Metrics
- Write throughput — spans/sec written to storage (Elasticsearch, Cassandra, Kafka, etc.)
- Write latency — storage write latency per span batch
- Storage size / growth rate — trace data volume; plan retention accordingly
- Read latency — trace lookup time; affects UI responsiveness
- Index size — for Elasticsearch: service name, operation name, tag indexes
- TTL / Retention effectiveness — are old traces being cleaned up on schedule
OpenTelemetry Collector Metrics
- otelcol_receiver_accepted_spans — spans received by the collector
- otelcol_receiver_refused_spans — spans refused (validation, backpressure)
- otelcol_exporter_sent_spans — spans exported to backend
- otelcol_exporter_send_failed_spans — export failures
- otelcol_processor_dropped_spans — spans dropped by processors (filtering, sampling)
- otelcol_exporter_queue_size — export queue depth (backpressure indicator)
- otelcol_process_memory_rss — collector memory usage
- otelcol_process_cpu_seconds — collector CPU usage
Trace Quality Metrics
- Instrumentation coverage — percentage of services with tracing enabled
- Context propagation breaks — traces that break across service boundaries (missing parent)
- Orphan spans — spans without a valid trace or parent (propagation failure)
- Clock skew — time drift between services causing negative span durations or incorrect ordering
- Span name cardinality — unique operation names; high cardinality = poor instrumentation (e.g., URL path as span name)
- Missing root spans — traces without the originating span
Alertable Patterns from Traces
- Latency outliers — traces with p99+ latency for deeper investigation
- Error trace patterns — common error paths across services
- Dependency failures — specific downstream services causing cascading errors
- Retry storms — traces showing multiple retry spans amplifying load
- N+1 query detection — traces with repeated identical DB spans in a loop
- Circular dependencies — service A → B → A detected in traces
- Fan-out explosion — single request spawning excessive parallel spans
Critical Alerts to Set Up
| Metric | Condition | Severity |
|---|---|---|
| Collector spans dropped | > 0 sustained | High |
| Collector queue length | growing unbounded | High |
| Storage write latency | > 500ms p99 | Medium |
| Trace error rate per service | > baseline + threshold | High |
| Trace end-to-end latency p99 | > SLA threshold | High |
| Orphan span rate | > 5% | Medium |
| Sampling rate drop | below configured target | Medium |
| Agent packets dropped | > 0 sustained | High |
| OTel Collector refused spans | > 0 sustained | High |
| Storage size | > 80% of provisioned | Medium |
Where to Get These
- Jaeger UI — trace search, service dependency graph, trace comparison, latency histograms
- Jaeger
/metrics— Prometheus endpoint on agent, collector, and query components - OpenTelemetry Collector
/metrics— internal telemetry endpoint - Grafana + Tempo — Grafana-native trace backend with exemplar linking to metrics
- Grafana Explore — trace-to-logs and trace-to-metrics correlation
- Service Performance Monitoring (SPM) — Jaeger’s built-in RED metrics derived from traces
- Trace Analytics — trace-derived service maps and latency breakdowns
- Prometheus + span metrics connector — OTel Collector generates RED metrics from spans
- Kibana APM — if using Elastic APM as trace backend
- AWS X-Ray / Datadog APM / New Relic — commercial alternatives with trace analytics
Tip: Early Warning Signals The most important early warning signals are collector spans dropped (losing observability data, can’t debug incidents), orphan span rate increase (context propagation breaking, traces becoming useless), and trace-derived error rate spikes (the fastest way to detect cross-service failures before individual service alerts fire).